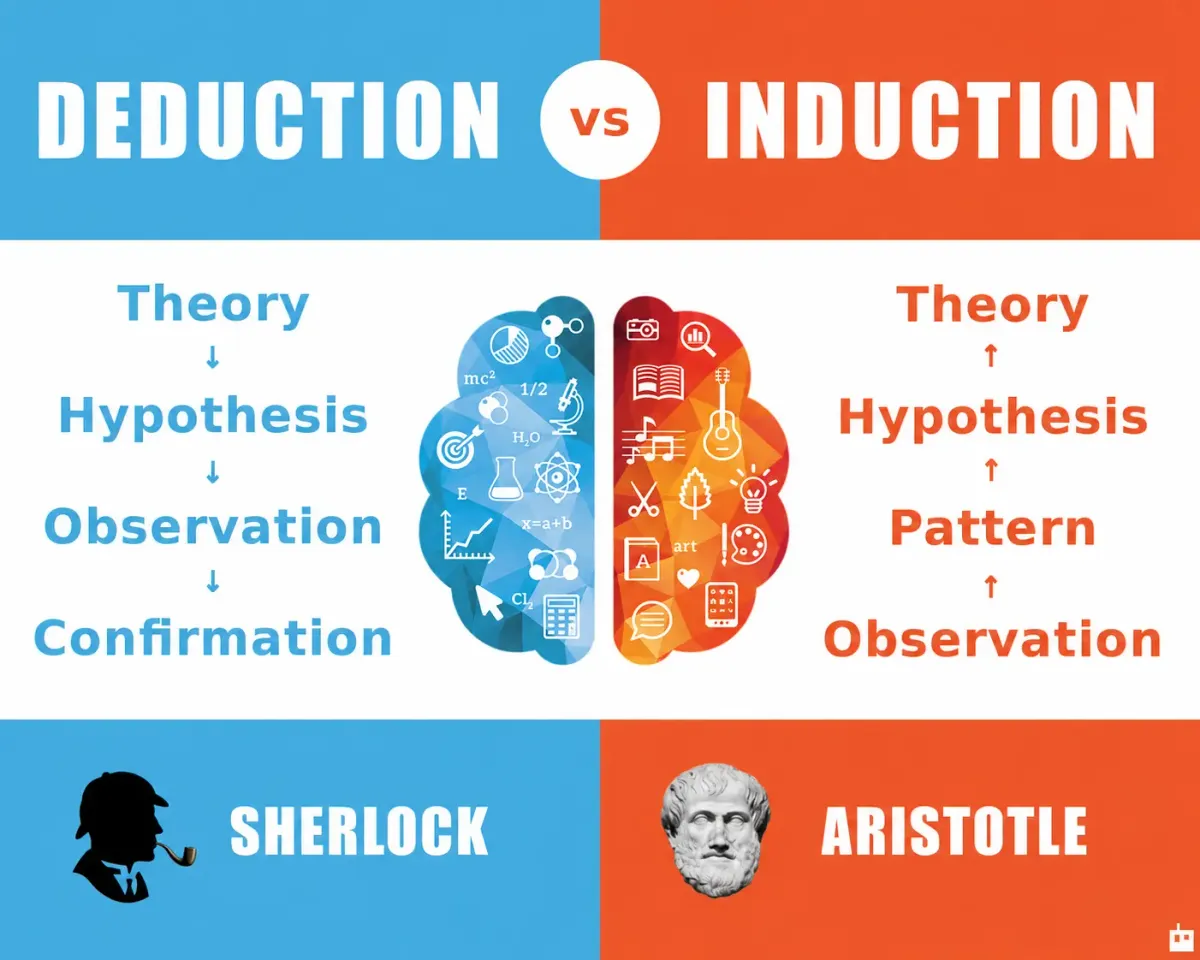
You know that moment when someone tells you, “LLMs reason,” and your brain instinctively responds: yeah… but how exactly do they reason?
That’s where the distinction gets really interesting—and, above all, useful if you’re building products with AI.
Deduction, induction, abduction: three “modes” of reasoning
We often lump everything together under the term “reasoning.” In practice, there are at least three very different mechanisms:
| Type | Example | Certainty |
|---|---|---|
| Deductive | All humans are mortal. Socrates is a human. Therefore, Socrates is mortal. | 100% if the premises are true |
| Inductive | I have seen 10,000 black crows. Therefore, all crows are probably black. | Only probable |
| Abductive | The ground is wet. It probably rained. | “Best available explanation” |
Deduction is “mathematical” reasoning: if the rules are clear and complete, you can prove it.
Induction is generalization based on observed cases.
Abduction is betting on the most plausible explanation.
The misunderstanding about LLMs
Many people imagine that a language model “reasons” mainly like a small logic solver, and thus primarily through deduction.
In reality, a huge part of what it does is more like induction and abduction.
When Claude or GPT tells you:
“I think this bug probably comes from this React component”
…that’s not a deduction.
It’s a statistical hypothesis based on millions of similar examples. In other words: “In situations similar to yours, that’s often what it was.”
Why they can be convincing… and wrong
And that perfectly explains this frustrating thing: LLMs can be very convincing while being completely off the mark.
A valid deduction doesn’t “hallucinate.” If the premises are true and the logic is correct, the conclusion is too.
But induction and abduction can be wrong—even when they’re reasonable.
A typical developer example:
- 1,000 Next.js projects had this bug.
- Your project looks like those projects.
- So your bug probably comes from there.
That’s induction.
And sometimes you’re part of the 0.1% of cases where that’s not true. Most of the time, though, induction works well enough that the shortcuts it provides are worth the occasional error. At least, I think so.
The best agents don’t “deduce”: they experiment
I would even say that today’s best agents (Claude Code, Codex, Kimi K2, etc.) aren’t primarily deduction engines.
They’re more like a loop of the following type:
- Observation
- Hypothesis
- Test
- New hypothesis
- Test
- …
It’s practically the scientific method: lots of abduction + induction + experimental verification, and relatively little pure deduction.
And that’s why the agents that “work” are rarely the ones who think the hardest —but the ones who:
- really read the code,
- run tests,
- inspect the logs,
- check the outputs,
- iterate quickly.
The key point: no complete axioms in the real world
And perhaps that is what intuitively bothers us: we are looking for a “universal reasoning engine.”
But a universal deductive engine only exists if the rules are perfectly defined.
Yet software development, UI design, business, product development, team management… these are open-ended problems. In these fields, there are no complete axioms.
So LLMs are forced to reason primarily through induction and abduction, just like we do.
And when you watch an agent code, they often resemble less a mathematician than an engineer making successive hypotheses until one of them holds up against reality.
The takeaway, if you’re building with AI: don’t ask “does the model know how to reason?” Instead, ask “does my system force it to verify?”
PS: Now that you know the difference, did you notice that Sherlock and Aristotle were actually inverted on the image?
Cheers 🍻
